
NIRVANA
[Airflow] airflow - spark 연동(YARN 및 Spark 복습) 본문
프로젝트를 진행하다보니 airflow에서 spark job을 실행해야 하는 일이 생겼다.
SparkSubmitOperator를 사용하여 spark job을 실행하기 위해서는 airflow에 설치 되어야 할 것들이 몇개 있다.
📌Airflow 설치 목록
- apache-airflow-providers-apache-spark 모듈(python)
- spark binary
- java
- hadoop aws
- aws-java-sdk-bundle
사실 뒤에 2개는 s3에서 파일을 읽어와야 해서 필요한 거고 앞에 3개만 있어도 된다.
먼저 SparkSubmitOperator에 대해 짧게 알아 보려고 한다(왜냐면 내가 SparkSubmitOperator 개념을 안 알아보고 하다가 3일 삽질을 했으므로)
SparkSubmitOperator는 Airflow가 Spark 클러스터에 애플리케이션을 제출할 때, spark-submit 명령을 실행하는 역할을 하게 된다.
spark-submit을 실행하기 위해서 spark와 java가 필요하고, spark-submit으로 실행할 스파크 애플리케이션이 실제로 실행될 spark worker를 결정하기 위해서 spakr master와의 연결 정보가 필요하다.
📌Airflow 설정
Dockerfile
- Java 설치( Java 11 설치 X 이슈)
- Spark 설치
- Hadoop-AWS SDK 관련 의존성 설치
FROM apache/airflow:2.9.1
USER root
RUN apt-get update && apt-get install -y \
curl \
unzip \
wget \
libnss3 \
libgconf-2-4 \
libx11-xcb1 \
libappindicator3-1 \
fonts-liberation \
xdg-utils \
&& rm -rf /var/lib/apt/lists/*
#Java 설치
RUN apt-get update && \
apt-get install -y openjdk-17-jdk
ENV JAVA_HOME /usr/lib/jvm/java-17-openjdk-amd64/
RUN export JAVA_HOME
#Spark 설치
RUN wget https://archive.apache.org/dist/spark/spark-3.5.3/spark-3.5.3-bin-hadoop3.tgz && \
tar -xvzf spark-3.5.3-bin-hadoop3.tgz && \
mv spark-3.5.3-bin-hadoop3 /opt/spark && \
rm spark-3.5.3-bin-hadoop3.tgz
ENV SPARK_HOME=/opt/spark
ENV PATH="&SPARK_HOME/bin:$PATH"
#Spark-aws
RUN wget -P -P $SPARK_HOME/jars/ \
https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-aws/3.3.2/hadoop-aws-3.3.2.jar \
https://repo1.maven.org/maven2/com/amazonaws/aws-java-sdk-bundle/1.11.901/aws-java-sdk-bundle-1.11.901.jar \
# Google Chrome 설치
RUN apt-get update && apt-get install -y wget && \
wget -q -O google-chrome.deb http://dl.google.com/linux/chrome/deb/pool/main/g/google-chrome-stable/google-chrome-stable_132.0.6834.159-1_amd64.deb \
&& apt install -y ./google-chrome.deb \
&& rm google-chrome.deb
# ChromeDriver 버전 확인 후 설치
RUN apt-get update && \
apt-get install -y wget unzip && \
wget -q -O chromedriver.zip https://storage.googleapis.com/chrome-for-testing-public/132.0.6834.159/linux64/chromedriver-linux64.zip && \
unzip chromedriver.zip
# 기본 유저로 복귀
USER airflow
docker-compose.yml
- pyspark 설치
- apache-airflow-providers-apache-spark 설치
_PIP_ADDITIONAL_REQUIREMENTS: ${_PIP_ADDITIONAL_REQUIREMENTS:- yfinance pandas numpy oauth2client gspread boto3 selenium webdriver-manager pyspark apache-airflow-providers-apache-spark}
Airflow connection 설정
spark master 연결 정보를 적어준다. Host와 port에 각각 정보를 작성하고, deploy mode를 client로 설정하였다.

💡도커 구성 정보
airflow와 spark 컨테이너는 각각 따로 빌드하되 같은 네트워크 안에 있도록 지정하여 서로 통신이 가능하도록 설정하였다.
📌Spark Job Application 작성
- AWS 연동 하지 않는 그냥 test 버전
from pyspark.sql import SparkSession
# Spark 세션 생성
spark = SparkSession.builder \
.appName("SimpleSparkApp") \
.master("local[*]") \
.getOrCreate()
# 예시 데이터 생성
data = [("Alice", 34), ("Bob", 45), ("Cathy", 29)]
columns = ["Name", "Age"]
# 데이터프레임 생성
df = spark.createDataFrame(data, columns)
# 데이터프레임 출력
df.show()
# 나이의 평균 계산
average_age = df.groupBy().avg("Age").collect()[0][0]
print(f"Average age: {average_age}")
# Spark 세션 종료
spark.stop()
- aws 연동 테스트 버전
from dotenv import load_dotenv
from datetime import datetime
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, IntegerType, StringType
import logging
import os
load_dotenv()
AWS_ACCESS_KEY_ID = os.environ.get("AWS_ACCESS_KEY_ID")
AWS_SECRET_ACCESS_KEY = os.environ.get("AWS_SECRET_ACCESS_KEY")
TODAY = datetime.now().strftime("%Y-%m-%d")
def create_spark_session():
spark = SparkSession.builder \
.appName("s3 read test") \
.config("spark.hadoop.fs.s3a.access.key", AWS_ACCESS_KEY_ID) \
.config("spark.hadoop.fs.s3a.secret.key", AWS_SECRET_ACCESS_KEY) \
.config("spark.hadoop.fs.s3a.endpoint", "s3.amazonaws.com") \
.getOrCreate()
return spark
def read_and_count_csv():
spark = create_spark_session()
df = spark.read.csv(f"s3a://yr-s3-project/final/spotify_join_data_2025-03-02.csv", header=True).coalesce(1)
row_count = df.count()
print(f'count: {row_count}')
logging.info(f'count: {row_count}')
if __name__ == "__main__":
read_and_count_csv()
📌Airflow DAG 작성
from airflow import DAG
from airflow.models import Variable
from airflow.providers.apache.spark.operators.spark_submit import SparkSubmitOperator
from datetime import datetime, timedelta
#DAG 기본 설정
default_args = {
'owner': 'yerin',
'depends_on_past': False,
'start_date': datetime(2025, 3, 2),
'retries': 1,
'retry_delay': timedelta(minutes=5)
}
with DAG(
dag_id='SparkAirflowTest',
default_args=default_args,
catchup=False,
tags=['final_project'],
schedule_interval='0 12 * * *'
) as dag:
spark_task = SparkSubmitOperator(
task_id = 'read_s3_csv',
application='dags/test_spark_ariflow.py', # 실행 파일 경로)
conn_id='spark_default', # 앞에서 설정한 spark master 연결 정보
verbose=True,
dag=dag
)
spark_task
📌결과
- AWS 연동 하지 않는 그냥 test 버전

- aws 연동 테스트 버전

세션 생성까지는 잘 실행되는데 AWS 파일을 읽어올 때 실행이 더 진행되지 않는 문제가 발생했다.
혹시 spark 어플리케이션 자체의 문젠가 싶어서 spark master에서도 실행을 해봤는데

spark master에서는 잘 된다...🥹
문제 해결:
https://nervertheless.tistory.com/233
[Airflow] airflow - spark INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0) 에서 멈춤 해결
https://nervertheless.tistory.com/232 [Airflow] airflow - spark 연동프로젝트를 진행하다보니 airflow에서 spark job을 실행해야 하는 일이 생겼다.SparkSubmitOperator를 사용하여 spark job을 실행하기 위해서는 airflow에
nervertheless.tistory.com
아무래도 Spark를 잘 이해하지 못한 상태에서 발생한 문제 같아서 YARN과 Spark 에 대해 짧은 복습을 진행했다.
YARN의 등장
- 하둡 2.0부터 세부 리소스 관리가 가능한 범용 컴퓨팅 프레임워크로 변경
- Map Reduce라는 고정 분산 프레임워크를 사용하는 것이 아닌 범용적인 컴퓨팅 시스템이 존재
- 이 범용 컴퓨팅 프레임워크가 바로 YARN → YARN 위에서 MapReduec, Spark와 같은 분산 처리 시스템이 동작하게 됨
YARN의 구성
- 리소스 매니저(Resource Manager) : 클러스터의 전체 리소스 관리 및 job 스케줄링 담당
- 노드 매니저(Node Manager) : 각 노드에서 실행, 컨테이너를 관리하고 리소스 모니터링 진행
- Container: 노드에 할당되는 자원 → 애플리케이션 마스터(Application Master)와 Task(사용자가제출한 코드)는 컨테이너 안에서 실행 됨
- 애플리케이션 마스터(Application Master): 개별 잡(Appilcation, task) 관리 및 리소스 할당 요청
- Container: 노드에 할당되는 자원 → 애플리케이션 마스터(Application Master)와 Task(사용자가제출한 코드)는 컨테이너 안에서 실행 됨
YARN의 동작
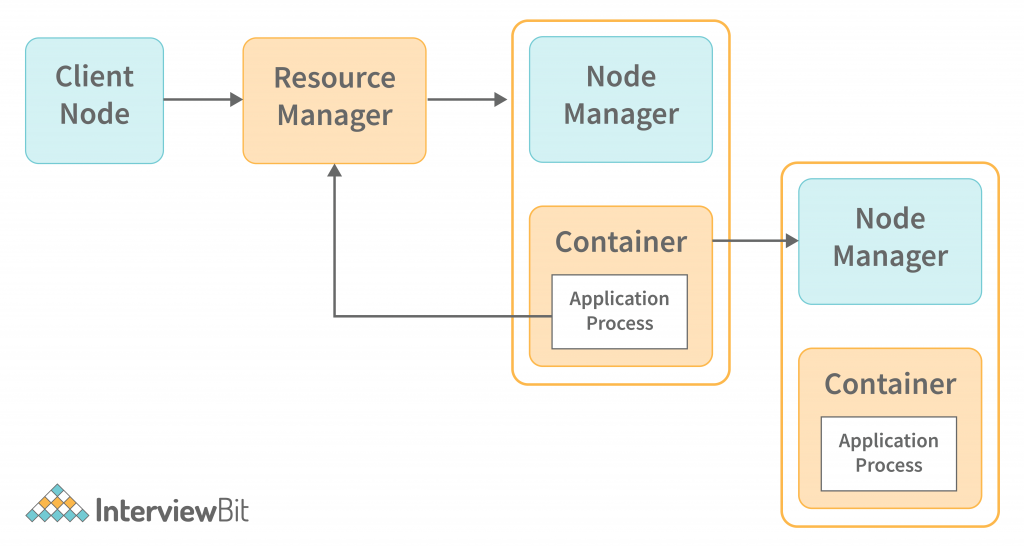
1. 클라이언트가 실행하고 싶은 코드와 환경설정 정보를 리소스 매니저(RM)에게 전달
2. 클라이언트가 제출한 코드 실행을 위해 리소스 매니저가(RM)가 Job을 할당할 노드 매니저(NM)에게 컨테이너 할당 및 애플리케이션 마스터(AM) 생성을 요청 → 노드 매니저가 AM 생성
3. 생성된 애플리케이션 마스터(AM)는 클라이언트가 제출한 코드 실행을 위해 필요한 자원을 리소스 매니저(RM)에게 요청
4. 애플리케이션 마스터(AM)는 리소스 매니저에게 할당 받은 자원(컨테이너)을 애플리케이션을 실제 동작 시킬 워커 노드 안의 노드 매니저(NM)에게 할당 → 노드 매니저(NM)는 할당 받은 자원을 기반으로 컨테이너 안에서 애플리케이션을 실행
5. 컨테이너 안에서 동작하는 task(애플리케이션)는 주기적으로 자신의 상황을 애플리케이션 마스터(AM)에게 리포트
SPARK (On YARN)
- 스파크 드라이버(Driver): 실행되는 노드의 마스터 역할을 수행, 즉 YARN의 Application Master
- 사용자가 제출한 코드를 실행하는 역할 → 실행 모드에 따라 실행 장소 차이 O
- AM의 역할이므로 리소스 할 및 자원 관리 진행
- Spark Session을 생성, 클러스터 매니저(Cluster Manager = Resource Manager) 및 액스큐터와 통신
- 사용자 코드를 실제 스파크 태스크로 변환, 스파크 클러스터에서 실행
- 스파크 액스큐터(Executor): 실제 Task를 실행하는 역할, 즉 YARN의 container
Spark Driver 실행 모드(On YARN)
Client Mode
- Driver(AM)가 Spark 클러스터의 바깥, 즉 컨테이너 바깥에서 동작
- local, airflow 등등..
- YARN AM은 컨테이너 안에서 최소한의 역할(컨테이너 요청)만 수행, 드라이버 역할은 하지 X
- 즉, AM != Driver
- executor만 YARN 컨테이너 안에서 실행 됨
Cluster Mode
- Driver(AM)가 Spark 클러스터, 즉 컨테이너 안에서 실행
- 이 때는 AM = Driver
아마 client 모드로 실행 되어서 spark driver가 airflow가 실행되는 컨테이너 안에서 생성 되어 리소스 관리 등을 지원하는데 내가 spark session을 작성할 때 할당할 cpu 등 자원을 제대로 작성하지 않은게...가장 큰 이유였던 것 같다..
기본으로 설정될 conf 파일도 없어서 리소스를 할당 받지 못해 기아 상태였던 듯!
'DataEngineering' 카테고리의 다른 글
| [Kafka] Kafka 구성 요소 살펴보고 간단 실습해보기 (0) | 2025.02.16 |
|---|---|
| [Airflow] 항공권 정보 ETL 파이프라인 만들어보기 (0) | 2025.02.02 |
| [Airflow] Airflow DAG 작성 연습 및 Backfill 이해하기 (3) | 2025.01.26 |
| [SnowFlake] S3버킷 연동 및 Json 데이터를 관계형 테이블에 로드 (2) | 2024.12.26 |
| 아파치 파케이(Parquet)와 열 지향 데이터베이스 (1) | 2024.09.22 |



