
NIRVANA
[1차 프로젝트] 컬리 데이터 크롤링하고 시각화하기 (1) 본문
프로젝트 개요
- 이커머스 상품 데이터와 상품 리뷰 데이터를 크롤링하고 시각화를 진행, 웹 사이트를 제작
- 상품 리뷰 데이터 크롤링을 통해 사용자가 상품의 특성을 빠르게 파악할 수 있도록 돕고 사용자의 구매력 향상에 초점을 둠
프로젝트 진행 과정
- 데이터 크롤링 및 수집(E) → 데이터 변환(T) 및 적재(L) → 시각화 및 웹 사이트 제작
- 간단한 ETL 과정을 거친 후, 데이터를 활용하는 것까지를 목표로 하였다.
- 우리 팀의 경우 카테고리 별로 역할을 나누었기에 각자 ETL 과정 및 시각화, 웹 사이트 제작을 목표로 했다
(근데... 시간 이슈로 ETL 과정(+ 백엔드)을 내가 진행한 방식대로 하게 되었다! 👍)
데이터 크롤링 및 수집 (E)
나는 건강식품 카테고리의 크롤링을 맡았다. 건강식품의 경우 총 450개의 데이터가 존재하는데 리뷰가 없는 데이터를 제외하니 총 데이터의 개수가 408개가 되었다.

컬리 사이트의 카테고리를 들어가보면 다음과 같이 상품의 이미지가 있고, 해당 상품을 클릭하면 상품의 상세 페이지로 넘어가게 되는 구조로 되어 있다. 따라서 데이터 크롤링을 진행할 때, 마우스 이벤트를 사용하여 리뷰 데이터를 크롤링하기 보단 상품 상세 페이지 url을 수집하여 리스트로 정의한 후, 해당 리스트를 순회하며 데이터를 크롤링 하는 편이 더 효율적이라고 판단했다.
상품 url 가져오기
#1차 드라이버 생성 -> 상품에 대한 url 가져오기
data_link = []
with webdriver.Chrome(service=Service()) as driver:
for i in range(1, 6): #총 5 페이지 -> 페이지네이션을 통해서 차례대로 접근
driver.get(f"https://www.kurly.com/categories/369?site=beauty&page={i}&per_page=96&sorted_type=1")
driver.implicitly_wait(10)
#div 태그 가져오기
div_tag =driver.find_element(By.XPATH, '//*[@id="container"]/div/div[2]/div[2]')
#a태그 개수 확인하기
a_tag_len = div_tag.find_elements(By.TAG_NAME, 'a')
#a태그 내의 href 가져오기
for i in range(1, len(a_tag_len)+1):
a_tags = div_tag.find_element(By.XPATH, f'//*[@id="container"]/div/div[2]/div[2]/a[{i}]')
href_value = a_tags.get_attribute('href')
data_link.append(href_value)
print(len(data_link))
각 페이지마다 보여지는 상품의 개수가 다르므로 상품의 각 페이지마다 제품의 상세 페이지 링크를 가지고 있는 a 태그의 개수를 확인하고, 태그 내의 href를 가져오도록 반복문을 진행했다.
상품 데이터 및 리뷰 데이터 가져오기
with webdriver.Chrome(service=Service()) as driver:
for i in range(len(data_link)):
driver.get(data_link[i])
time.sleep(1)
#상품 이름 가져오기
try:
product_name = driver.find_element(By.XPATH, '//*[@id="product-atf"]/section/div[2]/h1')
df.loc[i, 'product_name'] = product_name.text
except:
#raise(KeyboardInterrupt)
df.loc[i, 'product_name'] = '없음'
#상품 url
df.loc[i, 'url'] = data_link[i]
reviews = []
for j in range(2):
time.sleep(0.5)
for k in range(3, 13):
try:
product_review = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, f'//*[@id="review"]/section/div[2]/div[{k}]/article/div/p')))
reviews.append(product_review.text)
except:
print('do not find data')
pass
#버튼을 클릭해서 다음 리뷰 페이지로 넘어감
driver.implicitly_wait(5)
try: #버튼이 있는지 확인
button = driver.find_elements(By.CSS_SELECTOR, 'button.css-1orps7k.ebs5rpx0')[0]
if button and not button.get_attribute('disabled'):
ActionChains(driver).click(button).perform()
else:
print('last page')
break
except:
print('do not find the button')
print(f"Number of reviews collected for product {i}: {len(reviews)}")
for k, review in enumerate(reviews):
column_name = f'review_{k+1}'
df.loc[i, column_name] = review
컬리에서 상품 리뷰의 경우, 별도의 페이지네이션이 없으므로 마우스 이벤트를 통해 '다음' 버튼을 누르게 해야 한다. 이때, 처음에는 당연히 리뷰 데이터가 있을 거라고 생각하고 try-except 문을 사용하지 않았는데 리뷰가 없는 데이터가 있어서 에러가 발생했었다. 따라서 해당 부분을 try-except문으로 감싸고, 만약 리뷰 데이터가 없다면 바로 다음 데이터의 상세 페이지를 확인할 수 있도록 했다.
리뷰 데이터를 리스트에 저장하고, 가장 큰 반복문(i, 위에서 구한 데이터 상세 페이지 리스트)을 순회하는 i인자를 행의 순서로하여 한 상품에 대해 컬럼을 [ 상품명, reveiw_1, review_2, ..., review_20 ] 이렇게 저장할 수 있도록 했다.

그런데 개 큰 문제 🥹
다른 팀원이 상품명, review 이렇게 수집하는 편이 더 좋지 않겠냐고 말함..
리뷰 데이터 수집에 시간이 꽤 많이 걸려서 그냥 다 수집하고 pandas를 사용해서 데이터 프레임을 변경하는 편이 더 빠를 것 같다고 생각했다.
new_cols = ['product_name', 'review']
new_use_data = pd.DataFrame(columns=new_cols)
for i in range(len(use_data)):
product = use_data.loc[i][0]
for j in range(1, len(use_data.loc[i])):
new_use_data.loc[len(new_use_data)] = [product, use_data.loc[i][j]] #제품 이름, 리뷰 이렇게해서 컬럼에 추가
그래서 급하게 추가된 코드..
데이터 프레임에서 행을 기준을 반복문을 순회하고, 행에서 제품명을 추출한 뒤 다시 이중 반복문을 돌며 데이터 리뷰를 추출하여 새로운 데이터 프레임에 [제품명 + 리뷰] 이렇게 행으로 추가할 수 있도록 했다.
추가되는 행의 번호는 길이를 구해서 할 수 있도록 했다. 비효율적인 것 같아보이지만 이게 내 최선있음. 내 머리는 이것 밖에 생각을 못함
그래도 4시간 데이터 크롤링 vs 8초 이중 반복문 하면 당연히 반복문 압승이었다..🫵👍
+) 아 맞다 이미지 url 추가도 있었는데 이것도 그냥 똑같은 방식으로 상세 페이지 순회하면서 하나씩 크롤링 했다.. 그리고 제품명 같이 수집해서 그걸로 붙임! 나중에 기력 생기면 추가하겠습니다
아무튼 그래서 나온 최종 데이터 모습은 다음과 같다

product_name, space_chekced_review, image_link 로 구성되어 있다.
리뷰 데이터 전처리는 특수 문자, 이모티콘 제거 및 개행문자 제거, 띄어쓰기 교정만 진행했다.
사실 맞춤법 교정도 하고 싶었는데 hanspell에서 에러가 나서 진행을 못함..
데이터 변환 및 적재 (T+L)
처음에는 그냥 정적인 페이지만 만들자고 했는데, 그렇게 되면 웹 사이트 구축할 때 너무 안예쁘기도 하고(모든 리뷰 데이터를 시각화해서 하나의 페이지에 뿌리는게 말이 안됨) 또 이왕이면 데이터베이스를 사용하는 편이 더 좋을 것 같아서 검색 기능을 넣자고 제안드렸고 팀원 분들도 흔쾌하게 수락해주셨다. 😚
검색 기능을 추가하기 위해 가장 먼저 DB를 모델링 해보았다.
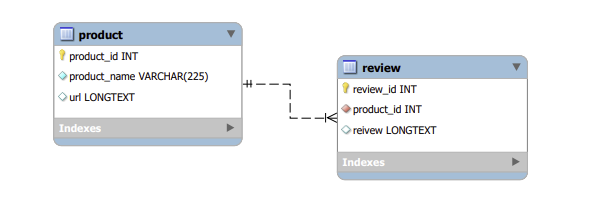
product 테이블의 product_id(PK)를 기반으로 review 테이블이 product 테이블을 참조하며 1:n 관계를 갖는다.
product테이블은 product_id, product_name, image_url을 컬럼을 가지게 된다. 원래 url 테이블을 따로 만드는게 맞나? 생각했었는데, 생각 해보면 상품 이미지 역시 상품 이름처럼 한 상품 당 하나의 이미지만 존재고, 유일하므로 product 테이블에 함께 있는게 맞다고 판단하였다.
review 테이블은 review_id(PK)와 product_id(FK), review를 컬럼으로 갖는다. 하나의 상품에 여러 개의 리뷰가 존재하므로 각 리뷰를 유니크하게 구분하기 위해 review_id를 PK로 사용할 수 있게 했다.
이렇게 테이블을 만들고 나서 내가 최종 완성한 데이터를 보니 데이터의 형태를 변환해야 할 필요성이 너무너무 많이 느껴졌다 (ㅋㅋㅋㅋㅋ..) 사실 처음에 크롤링 했던 데이터 파일을 그대로 사용하면 DB에 데이터를 넣는 게 쉬웠겠지만 이왕 프로젝트를 하는 김에 데이터를 알맞게 변환해보자! 해서 어떻게 하면
[상품명] [리뷰] [이미지 url] 로 이루어진 데이터를 내가 설계한 데이터 베이스에 넣을 수 있을지 진.고(진지한 고민이라는 뜻)하기 시작했다.
product 테이블에 들어갈 수 있는 데이터로 변환하기
import pandas as pd
#데이터 읽어오기
df = pd.read_csv('뷰티컬리_전처리_이미지_데이터_최종.csv')
#컬럼 확인
df.columns
#제품명, 이미지링크를 unique함수를 사용 -> 하나씩만 뽑아서 np 배열로 저장
product = df['product_name'].unique()
product_url = df['image_link'].unique()
#새 데이터프레임 생성
columns = ['product_id', 'product_name', 'url']
new_data = pd.DataFrame(columns=columns)
#product 데이터 프레임 생성
for name, url in zip(product, product_url):
id = len(new_data) #new_data 데이터 프레임의 크기로 id 정하기(어차피 상품은 고유하니까)
new_data.loc[id, 'product_id'] = id
new_data.loc[id, 'product_name'] = name
new_data.loc[id, 'url'] = url
new_data.head()
new_data.to_csv('뷰티컬리_건강식품_product.csv', encoding = 'utf-8-sig')
제품명과 이미지 링크는 한 상품에 대해 유니크하므로 기존 데이터에서 unique() 함수를 사용하여 어떤 제품과 해당 제품에 대해 어떤 url이 있는지를 넘파이 배열로 먼저 정의하였다.
이후, product 테이블의 컬럼을 기반으로 새 데이터 프레임을 생성하고, zip()함수로 상품 이름과 상품 url 넘파이 배열을 묶어서 함께 순회 → 새데이터 프레임 한 행의 각 컬럼에 알맞는 데이터를 넣을 수 있도록 했다.
이때, 데이터를 추가할 행의 길이는 역시 데이터 프레임의 길이(안에 들어간 원소의 개수)로 구했다...ㅎ 진심. 이거 말고는 방법이 생각이 안남 (더 좋은 방법 있으면 알려주세요... 🙇♀️)
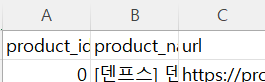
아무튼 이렇게 csv 데이터로 변환함!
review 테이블에 들어갈 수 있는 데이터로 변환하기
#제품명, 제품 리뷰로 새 데이터 프레임 생성
data = df[['product_name','space_checked_review']]
data.head()
product_dict = {} #제품이름:제품아이디
prouct_id = 0 #
review_data = [] #한번에 데이터 프레임으로 변환 위함
for i in range(len(data)):
product = data.iloc[i, 0] #제품 이름
review = data.iloc[i, 1] #리뷰 데이터
if product in product_dict: #만약 제품이 딕셔너리에 있다면
id = product_dict[product] #제품 id는 해당 제품에게 이미 부여된 id
else: #만약 제품이 딕셔너리에 없다면
product_dict[product] = prouct_id #딕셔너리에 추가
id = prouct_id #리뷰 데이터에 들어가는 id 정의
prouct_id +=1 #product_id 1증가
review_data.append({ #리뷰 레코드 생성
'review_id': i,
'product_id': id,
'review': review
})
review_table = pd.DataFrame(review_data) #리스트를 데이터 프레임으로 변환
review_table.tail()
review_table.to_csv('뷰티컬리_건강식품_reviw.csv', encoding = 'utf-8-sig')
리뷰 데이터를 review 테이블에 들어갈 수 있는 데이터로 변환하는 부분이 너무너무 어려웠고 꽤 오래 고민했다.
제품에 대한 데이터(상품명, 이미지 링크)는 다 고유하기 때문에 product_id도 순차적으로 증가하면 되었지만, review 데이터의 경우 product_id는 같은 상품(같은 상품 이름)에 대해서는 같은 id값을 유지해야 하기 때문에 해당 부분을 어떻게 처리할 수 있을지가 가장 큰 고민 지점이었다. 그래서 고민하다가 생각한 방법이 딕셔너리를 사용하는 것이었다.
상품이름(key): 상품id(value) 로 갖는 딕셔너리를 정의하고, 순회할 데이터를 [상품 이름, 리뷰] 로 이루어지도록 변경했다. 데이터를 순회하면서 상품 이름이 딕셔너리 안에 있다면, 상품 이름을 key로 상품 id를 가져와 product_id로 설정할 수 있게 하고 딕셔너리 안에 없다면, 해당 상품을 딕셔너리에 추가하고, product_id를 1 증가하여 다음 상품에 대한 id를 설정할 수 있도록 했다.
리뷰 id는 유니크하니까 그냥 순차적으로 증가하는 for 문의 반복인자 i를 사용해서 추가했다.
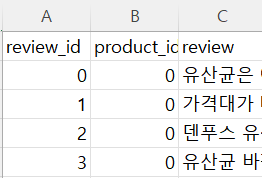
리뷰 데이터도 잘 변환했다 😎
이제 해당 데이터를 생성한 DB 테이블에 넣기만 하면 된다.
테이블에 csv 데이터 넣기
import os
#장고 모델 가져오는것보다 항상!!! 위에 있어야 함 -> 안그럼 오류
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "health_food.settings")
import django
django.setup()
import pandas as pd
import csv
from healthy.models import product, review
PRODUCT_PATH = "C:/Users/ryeon/Documents/YerinShin/DevCourseDE/first_project/data/뷰티컬리_건강식품_product.csv"
REVIEW_PATH = "C:/Users/ryeon/Documents/YerinShin/DevCourseDE/first_project/data/뷰티컬리_건강식품_reviw.csv"
df1 = pd.read_csv(PRODUCT_PATH)
print(df1.columns)
for _, row in df1.iterrows():
product_obj, created = product.objects.get_or_create(
product_id = row['product_id'],
defaults={
"product_name": row["product_name"],
"image_url": row['url']
}
)
df2 = pd.read_csv(REVIEW_PATH)
for _, row in df2.iterrows():
review_obj, created = review.objects.get_or_create(
review_id = row['review_id'],
defaults={
"product_id": product.objects.get(product_id=row["product_id"]),
"review_data": row["review"],
}
)
진짜 간단하게 각 행을 읽고, 해당 행에서 테이블의 컬럼과 일치하는 컬럼을 데이터로 넣어서 테이블에 데이터를 넣었다.
+) 장고에서 모델 임포트 할 때 꼭꼭 장고 설정 세팅을 먼저 하기.. 오류 왜 나는지 계속 노려보기만 했음...영원히...
아...장고로 웹 페이지 만들 때도 진짜진짜 많은 일들이 있었는데 너무 힘들어서 일단 ETL 부분만 정리...함
그래도 이번 프로젝트 할 때 일지를 매일 써서 프로젝트 정리가 후딱 끝나네요 좋다(..^_^)
최종 코드 올릴 때 크롤링 코드를 올리는게 조금 애매해서(아무래도 크롤링은 각자 진행했으니까) 그냥 데이터 변환하는 코드는 슬랙으로 공유했는데 그냥 깃에 올릴 걸..이란 후회가 조금 남아여 그래도 데이터 테이블에 넣는 코드는 있음!
사실 멘토님이 시각화 툴로 아파치 superset을 추천해주셔서 이걸로 시각화 해보고 싶었는데 시간 이슈로 못함.. 암튼 자세한 내용은 장고 웹페이지 + 시각화랑 회고할 때 좀 더 정리해봐야지
팀 깃허브🐹
https://github.com/5LineKurlyProject/kurly_project
GitHub - 5LineKurlyProject/kurly_project: Kurly Data Crawling
Kurly Data Crawling . Contribute to 5LineKurlyProject/kurly_project development by creating an account on GitHub.
github.com
'Project' 카테고리의 다른 글
| ubuntu 환경에서 eventsim 설치 및 실행하기 (0) | 2025.02.25 |
|---|---|
| [LXC] Ubuntu 환경에서 LinuX Containers 사용하기 (0) | 2024.08.19 |
| [SpringBoot] 스프링부트 찍먹해보기 (0) | 2024.03.19 |

