
NIRVANA
[Apache Airflow] 웹 크롤링 DAG 작성하기 본문
(복습을 위해 살펴보는) Airflow 구조

Scheduler
- 스케줄된 Workflow(DAG)을 트리거하고 제출된 Task를 실행(조건을 만족할 경우, Task를 실행할 수 있게 함)
- executor에게 Task를 제공해주는 역할을 수행
- 생성된 DAG를 지속적으로 모니터링하고, 종속성 및 타이밍 구성에 따라 실행할 작업을 예약한다
Executor
- Task를 수행하는 역할
- 스케줄러와 통신하여 실행할 작업에 대한 정보를 받고, 다음 작업을 실행하는 데 필요한 프로세스나 컨테이너를 시작한다
- 인프라나 요구사항에 따라 LocalExecutor, CeleryExecutor, KubernetesExecutor 등 다양한 유형의 실행자가 존재
Worker
- Executor가 할당한 작업을 수행하는 구성 요소 (실제 Task 실행 주체)
- 선택한 Executor에 따라 별도의 프로세스나 컨테이너일 수 있으며, 작업에 정의된 실제 코드나 스크립트를 실행하고 해당 상태를 다시 executor에게 보고한다
WebServer
- DAG와 Task의 동작을 트리거하고 디버그 하기 위한 사용자 인터페이스
- DAG 시각화, 모니터링 등 관리 가능 및 이슈 해결을 위한 대시보드 제공
Metadata Database
- scheduler, executor, Web Serve에서 상태를 저장하기 위해 사용하는 데이터베이스
- 작업 및 실행 기록에 대한 정보를 저장
- PostgerSQL, MySQL, SQLite 등을 지원
(복습을 위한) Airflow DAG 작성해보기
from airflow import DAG
from airflow.operators.bash import BashOperator
from datetime import datetime, timedelta
from textwrap import dedent
with DAG(
"tutorial",
default_args={
"depends_on_past": False,
"email": ["airflow@example.com"],
"email_on_retry": False,
"email_on_failure": False,
"retries": 1,
"retry_delay": timedelta(minutes=5),
"queue": "bash_queue",
"pool": "backfill",
"priority_weight": 10,
"end_date": datetime(2025, 1, 1),
"wait_for_downstream": False,
"sla": timedelta(hours=2),
"execution_timeout": timedelta(seconds=300),
#"on_failure_callback": some_function or list of functions
#"on_success_callback": some_function or list of functions
#"on_retry_callback: some_function or list of functions
#"sla_miss_callback": some_function or list of functions
"trigger_rule": "all_success"
},
description="A simple tutorial DAG",
schedule_interval="0 0 * * *",
start_date=datetime(2024, 9, 14),
catchup=False,
tags=["example"],
) as dag:
t1 = BashOperator(
task_id = "print_date",
bash_command="date",
)
t2 = BashOperator(
task_id = "sleep",
depends_on_past=False,
bash_command="sleep 5",
retries=3,
)
t3 = BashOperator(
task_id = "templated",
depends_on_past=False,
bash_command=templated_command,
)
t1 >> [t2, t3]with DAG(...) as dag: 구문
- DAG을 컨텍스트로 생성하고 Task를 정의할 수 있게 함
default_args 딕셔너리
- DAG 내의 각 Task에 공통으로 적용될 기본 설정 값 정의
default_args={
"depends_on_past": 이전 Task 실행의 성공 여부에 따라 현재 Task 실행 여부 결정
"email": Task 실패 시 이메일을 받을 사람들의 목록 정의
"email_on_retry": Task가 재시도될 때 이메일을 보낼지 여부 설정
"email_on_failure": Task가 실패했을 때 이메일 보낼지 여부 설정
"retries": Task 실패 시 재시도할 횟수 지정
"retry_delay": Task가 실패한 후 재시도하기 전, 기다리는 시간 지정
"queue": Task가 실행될 작업 큐 지정
"pool": 리소스 제한을 위해 사용되는 풀 지정
"priority_weight": Task 우선순위 지정, 값이 클 수록 높은 우선순위이며 리소스가 제한 된 경우 우선적으로 실행
"end_date": Task가 더 이상 실행되지 않는 종료 날짜 지정
"wait_for_downstream": 현재 Task 성공 시, 하위 Task가 모두 완료될 때까지 기다릴지 여부 설정
"sla": 서비스 수준 계약 시간
"execution_timeout": Task가 완료되어야 하는 시간, 지정된 시간 내에 완료되지 않으면 실패로 간주
"on_failure_callback": Task 실패 시 호출되는 콜백 함수
"on_success_callback":Task가 성공적으로 완료되었을 때 호출되는 콜백 함수
"on_retry_callback: Task가 재시도될 때 호출되는 콜백 함수
"sla_miss_callback": SLA 미준수 시 호출되는 콜백 함수
"trigger_rule": Task가 실행될 조건 정의
}
Task정의
t1 = BashOperator(
task_id = "print_date",
bash_command="date",
)
t2 = BashOperator(
task_id = "sleep",
depends_on_past=False,
bash_command="sleep 5",
retries=3,
)
t3 = BashOperator(
task_id = "templated",
depends_on_past=False,
bash_command=templated_command,
)
t1 >> [t2, t3] #t1 성공 시 t2와 t3 병렬 실행
AWS EC2에 Airflow설치하기
EC2 내에서 가상환경을 설정하고 진행하기 위해 필요한 몇가지 설정을 진행해줬다
sudo apt-get update
sudo apt-get install python3-virtualenv
virtualenv airflow
cd airflow
source bin/activate #가상환경 활성화
pip install apache-airflow
export AIRFLOW_HOME=~/airflow
echo $AIRFLOW_HOME
#db 초기화
airflow db init
#사용자 계정 생성
airflow users create \
--username admin \
--firstname {firstname} \
--lastname {lastname} \
--role Admin \
--email {email주소}
Airflow Web UI를 8080 포트에 띄우기 위해 인바운드 규칙에서 8080 포트를 허용하도록 인바운드 규칙을 수정한다.

airflow webserver --port 8080
퍼블릭 IPv4 주소:8080으로 들어가면 Airflow 로그인 페이지가 나온다. 거기서 이전에 유저를 생성하며 만들었던 대로 입력하면

이렇게 웹 서버가 잘 동작하는 것을 확인할 수 있다!
mkdir dags
#sudo apt-get update
#sudo apt install nano
nano airflow.cfg
airflow.cfg 파일을 살펴보면 dags_folder 변수에 DAG가 저장되는 디렉토리를 지정한다는 걸 알수 있다. 기본 값은 /home/ubuntu/airflow/dags 이다. dags 파일을 mkdir로 생성한다.
+) 기본 예제 DAG를 삭제(?)하기 위해 airflow.cfg 파일 load_examples 변수를 False로 설정한다.
DAG 파일 작성하기
- start → get_info_task → msg → end 순으로 실행
- start, end로 각각 시작과 끝에 메시지 출력
- get_info_task로 클롤링 파이썬 스크립트 실행
- msg로 실행 결과 출력
- 1시간에 1번씩 DAG 실행
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.operators.python import PythonOperator
from airflow.utils.trigger_rule import TriggerRule
from datetime import datetime, timedelta
import sys, os
def print_result(**kwargs):
r = kwargs["ti"].xcom_pull(key='result_msg')
print("message:", r)
with DAG(
"crawling-recruiting",
default_args = {
'depends_on_past': False,
'email' : ['likeeu23@naver.com'],
'email_on_failure': True,
'email_on_retry': True,
'retries': 1,
'retry_delay': timedelta(minutes=30),
},
description="job opening crawling",
schedule=timedelta(hours=1),
start_date=datetime(2024, 9, 15),
catchup=False,
tags=['crawling_example'],
) as dag:
start = BashOperator(
task_id ='start',
bash_command='echo "start"',
)
get_info_task = BashOperator(
task_id = 'run_get_info',
bash_command='python3 crawling_recruiting.py',
)
msg = PythonOperator(
task_id = 'msg',
python_callable=print_result,
provide_context=True,
)
complete = BashOperator(
task_id = 'complete',
bash_command='echo "complete!" ',
)
start >> get_info_task >> msg >> complete
dags list로 확인하면 dag가 잘 등록 된 것을 확인할 수 있다
크롤링 파일 작성하기
크롤링 알못이어서 코드 참고했습니다..! (https://github.com/sesac-google-ai-1st/saramin-repo-2/blob/main/crawling.py)
# -*- encoding: euc-kr-*-
import time
import selenium
from selenium import webdriver
import pandas as pd
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service as ChromeService
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option("useAutomationExtension", False)
options.add_argument('log-level=3')
import warnings
warnings.filterwarnings('ignore')
driver = webdriver.Chrome()
url = 'https://www.saramin.co.kr'
driver.get(url)
time.sleep(1.5)
search ="정보보호"
driver.find_element(By.CSS_SELECTOR, 'button#btn_search.btn_search').click()
time.sleep(1.5)
search_bax = driver.find_element(By.TAG_NAME, 'input')
search_bax.send_keys(search)
time.sleep(1.5)
driver.find_element(By.CSS_SELECTOR, 'button#btn_search_recruit.btn_search').click()
time.sleep(1.5)
info_list_all = driver.find_elements(By.XPATH, '//*[@id="recruit_info_list"]/div[1]/div')
info_list_addr = driver.find_elements(By.XPATH, '//*[@id="recruit_info_list"]/div[1]/div/div/h2/a')
next_buttom = len(driver.find_elements(By.XPATH, '//*[@id="recruit_info_list"]/div[2]/div/a'))
df = pd.DataFrame()
for i in range(10):
info_list_all
info_list_addr
info_list_all_inner = [i.get_attribute('innerText') for i in info_list_all]
time.sleep(3)
info_list_addr_href = [i.get_attribute('href') for i in info_list_addr]
time.sleep(3)
df = pd.DataFrame({
'info': info_list_all_inner,
'link': info_list_addr_href
})
time.sleep(5)
try:
for j in range(next_buttom):
refix_buttom = driver.find_elements(By.XPATH, '//*[@id="recruit_info_list"]/div[2]/div/a')[j]
time.sleep(3)
refix_buttom.click()
time.sleep(3)
time.sleep(10)
df = pd.concat([df, pd.DataFrame({
'info': info_list_all_inner,
'link': info_list_addr_href
})])
time.sleep(5)
except:
break
finally:
df.to_csv('data.csv', index=False)
driver.close()
이렇게 잘 크롤링 된 것을 확인할 수 있었다!
ubuntu에서 Selenium 실행할 수 있도록 환경 세팅하기
아직 ubuntu에서는 크롬 드라이버를 설치해줘야 한다길래,,,드라이버 설치도 함께 진행해줬다.
apt-get update
wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb
sudo apt install ./google-chrome-stable_current_amd64.deb
google-chrome -version
#sduo apt install unzip
wget https://storage.googleapis.com/chrome-for-testing-public/128.0.6613.137/linux64/chromedriver-linux64.zip
unzip chromedriver-linux64.zip
크롬드라이버 설치
크롬드라이버 다운로드 https://googlechromelabs.github.io/chrome-for-testing/https://andamiro1.tistory.com/31 - 크롬 드라이버 Chromedriver 128버전 리눅스 64비트(Chromedriver version 128 Linux 64 bit)- https://storage.googleapis.com
dalgalim.tistory.com

options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
driver=webdriver.Chrome(excutable_path='./chromedriver-linux64/chromedriver', chrmoe_options=options)
크롤링 코드에 ubuntu환경에서 사용하기 위해 필요한 내용을 추가해주었다.
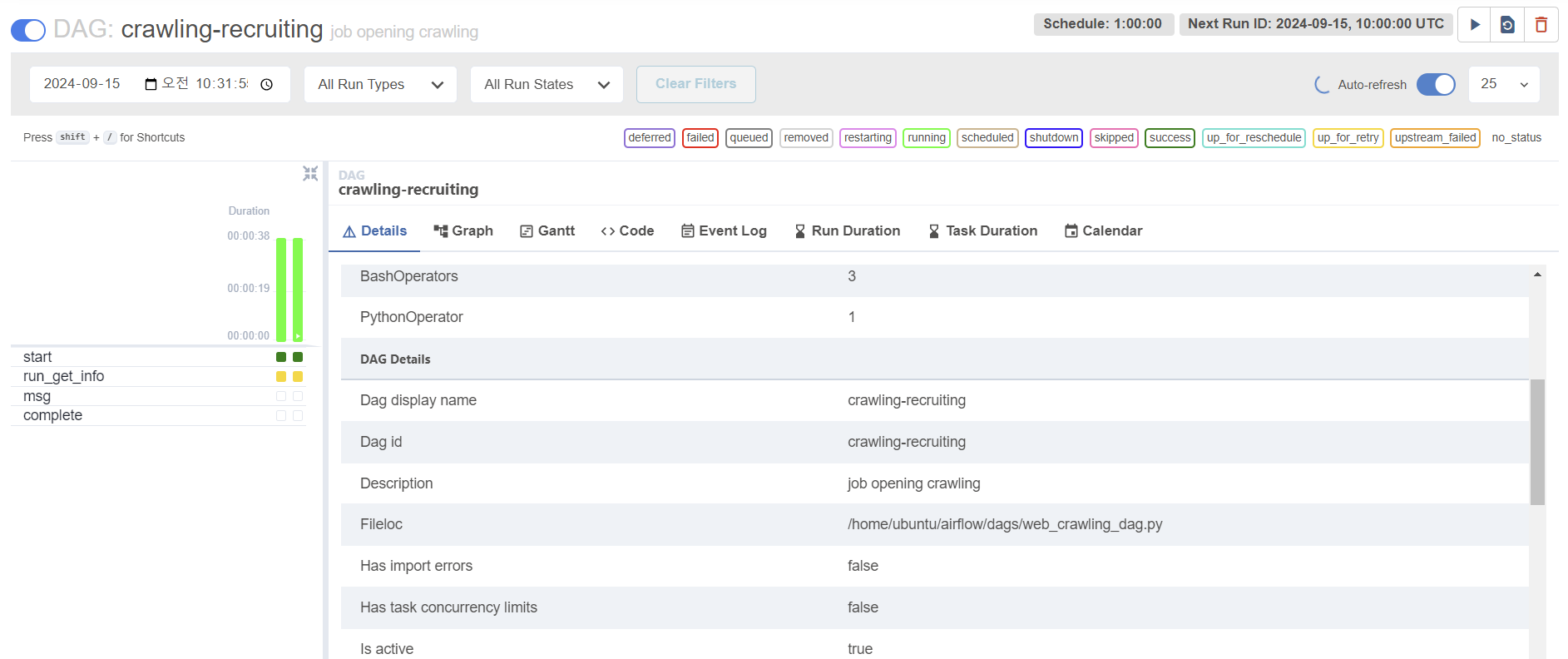
그러고 냅다 트리거 시키기면!! 정의해놓은대로 DAG가 실행된다.
근데 크롤링 하는 task 상태가 up_for_retry여서 로그를 확인해봤다.
airflow.exceptions.AirflowException: Bash command failed. The command returned a non-zero exit code 2.
BashOperator 부분에서 명령어 실패했다는 건데 뭔가 느낌적으로 무좍건 크롤링 코드 실행하는 부분에서 오류 났을 것 같음!
그래서 수정하려고 했는데..

왜 무한 로딩인데요 선생님..

오류 난 부분 수정하고.. 크롤링한 파일 S3에 적재해오는 건 다음에 해오겠습니다....
참고:
https://github.com/sesac-google-ai-1st/saramin-repo-2
https://velog.io/@dbgpwl34/EC2ubuntu%EC%97%90-airflow-%EC%84%A4%EC%B9%98
'DataEngineering' 카테고리의 다른 글
| [SnowFlake] S3버킷 연동 및 Json 데이터를 관계형 테이블에 로드 (2) | 2024.12.26 |
|---|---|
| 아파치 파케이(Parquet)와 열 지향 데이터베이스 (1) | 2024.09.22 |
| [ElasticSearch]시맨틱 검색(Semantic Search)이란? (6) | 2024.09.01 |
| [Kafka & Spark] 실시간으로 사람 detect하고 집계 테이블 만들기(2) (0) | 2024.08.25 |
| [Apache Kafka] 실시간으로 사람 detect하고 집계 테이블 만들기 (2) | 2024.08.18 |



