
NIRVANA
[Apache Kafka] 아파치 카프카란? 본문
Apache Kafka란?
- 실시간으로 스트리밍 데이터를 수집, 처리하는 데 최적화된 분산 데이터 스토어
- 여러 소스에서 데이터 스트림을 처리하고 여러 사용자에게 전달하는 역할
- 필요한 모든 곳에 대규모 데이터를 동시 이동 가능
- 실시간 스트리밍 데이터 파이프라인과 애플리케이션을 구축하는 데 주로 사용
- 메시징, 스토리지, 스트림 처리를 결합하 과거 데이터를 비롯하여 실시간 데이터의 저장 및 분석을 허용
ex) 사용자 활동 데이터를 기반, 사람들이 웹 사이를 어떻게 사용하는지 실시간으로 추적하는 파이프라인 구축
Kafka의 세 가지 주요 기능
- 레코드 스트림 게시 및 구독
- 레코드가 생성 순서대로 레코드 스트림을 효과적으로 저장 진행
- 레코드 스트림의 실시간 처리
✨ 스트리밍 데이터: 수천 개의 데이터 원본에서 연속적으로 생성되는 데이터, 보통 데이터 레코드를 동시에 전송한다.
✨ 레코드: 관계형 데이터베이스 테이블의 가로 방향 (행) / 파티션에 저장된 데이터
메시지 큐(Message Queue)란?
1. 메시지 큐
- 메시지 지향 미들웨어(MOM: Message Oriented Middleware)를 구현한 시스템, 프로그램 간의 데이터를 교환할 때 사용

구성요소
1. 프로듀서(Producer)
- 메시지를 생성, 큐에 넣는 역할
- 프로듀서는 여러 개일 수 있으며, 다양한 소스에서 데이터를 큐로 전송
2. 큐(Queue)
- 메시지가 저장되는 중간 저장소
- 큐는 일반적으로 FIFO 원칙을 따름
3. 컨슈머(Consumer)
- 큐에서 메시지를 읽어 처리하는 역할
- 컨슈머는 메시지를 하나씩 읽고, 처리한 후 큐에서 제거
동작 방식
- 메시지는 프로듀서에 의해 큐에 넣어지며, 컨슈머는 큐에서 메시지를 읽은 후 처리
- 각 메시지는 하나의 컨슈머에 의해 처리 됨
- 즉, 메시지는 한 번만 전달 되고 처리 됨
- 큐의 길이가 길어질 경우, 메시지가 지연될 수 있으며 큐가 가득 찰 경우 메시지를 받을 수 없음
단점
- 메시지 손실 가능성: 메시지가 큐에서 제거된 후에만 컨슈머가 처리 가능 하므로, 처리 중에 문제가 발생하면 메시지가 손실 될 수 있음
- 확장성 제한: 대규모 분산 시스템에서의 확장성은 제한적일 수 있음
Kafka 작동 방법
- Pub-Sub 모델의 메시지 큐 형태로 동작
- 메시징 시스템에서 데이터를 발생하고 구독하는 방식
주요 구성 요소
1. 토픽(Topic)
: 카프카에서 메시지를 구분하는 단위
- 메시지 스트림을 분류하는 논리적 단위
- 각 토픽은 이름을 가지며 메시지는 특정 토픽으로 발행됨
- ex) 'logs', 'transactions' 등
2. 파티션(Partition)
: 메시지의 구분 단위, 여러 개의 파티션으로 구성 됨
- 각 토픽은 여러 파티션으로 나누어지며, 파티션은 메시지의 순서를 보장하는 단위가 됨
- 파티션에 들어간 데이터는 파티션 내에서 고유한 번호(offset)을 가지게 됨
- 컨슈머가 데이터를 어느 지점까지 읽었는지 확인하는 용도로 사용
- 따라서, 장애로 인해 재실행 했을 경우 중지된 시점을 알고 있으므로 해당 시점부터 다시 실행할 수 있음
- 각 파티션은 독립적으로 메시지를 저장하고 관리하며, 병렬 처리를 가능하게 함
- 큐와 비슷한 구조, FIFO처럼 먼저 들어간 레코드는 컨슈머가 먼저 가져가게 됨
- 단, 데이터를 가지고 간다고 레코드가 삭제되지는 않음
- 즉, 다른 컨슈머가 다시 0번 부터 가져갈 수 있음 (단, 다른 컨슈머 그룹에 있어야 함)
3. Producer
: 정보를 제공하는 자
- 토픽에 해당하는 데이터를 생성, 특정 토픽에 메시지를 발행하는 역할 수행
- 프로듀서는 메시지 발행 시, 메시지가 어떤 파티션에 저장될지를 결정함
- 해당 결정은 라운드 로빈, 메시지 키를 사용한 해싱 등을 사용하여 이루어짐

producerRecorder: 프로듀서에서 생성하는 레코드, 오프셋 미포함
send(): 레코드 전송을 요청하는 메서드
Partitional: 어느 파티션으로 전송할지 지정하는 파티셔너, 기본 값으로 Default Partitional로 지정
Accumulator: 배치로 묶어 전송할 데이터를 모으는 버퍼
4. Consumer
- 토픽의 파티션으로부터 데이터를 polling하는 역할을 수행
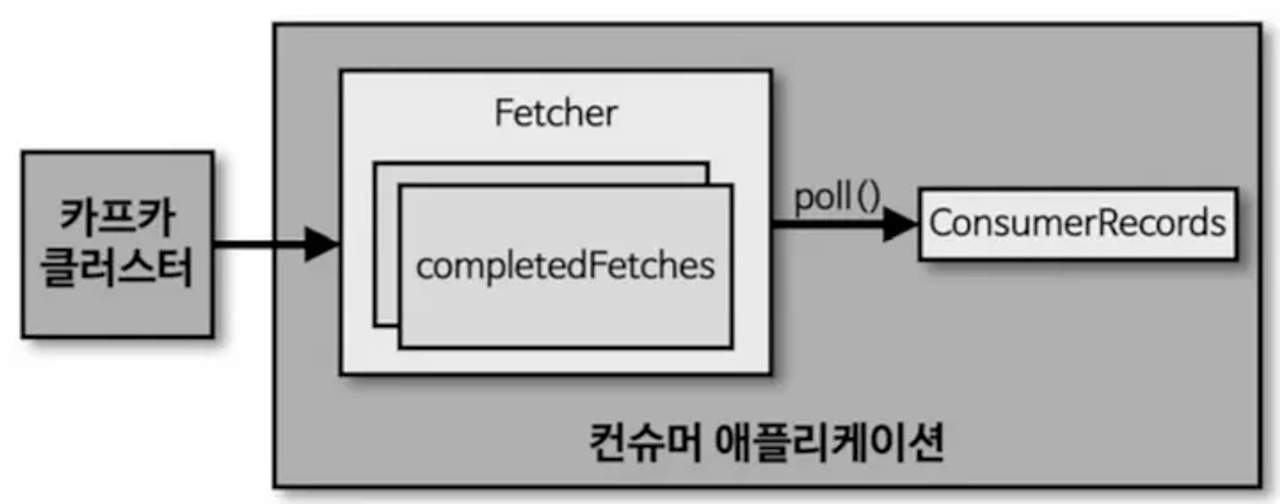
- Fetcher: 리더 파티션으로부터 레코드를 가지고와 대기하는 곳
- poll(): Fetcher에 있는 레코드를 리턴
- ConsumerRecord: 처리하고자 하는 레코드 모임

5. Consumer Group
: 여러 파티션을 가진 토픽에 대해 컨슈머를 병럴 처리할 때 사용
- 동일한 그룹에 속한 컨슈머들은 토픽의 파티션을 서로 나누어 병렬로 처리하게 됨
- 각 파티션은 하나의 컨슈머에게만 할당, 그룹 내에서 메시지가 중복 처리 되지 않도록 함
- 여러 컨슈머 그룹이 동일한 토픽을 구독할 수 있으며 이는 메시지가 여러 번 처리 됨을 의미
데이터 흐름

1. 발행 (Publish)
- 프로듀서가 데이터를 생성하고, 이를 메시지 형태로 측정 토픽에 발행
- 발행된 메시지는 토픽 내의 파티션에 순차적으로 저장
2. 구독(Subscribe)
- 컨슈머는 특정 토픽을 구독, 해당 토픽의 메시지를 읽어들임
- 컨슈머 그룹을 사용할 경우, 그룹 내의 각 컨슈머는 파티션을 나누어 읽음
- 병렬 처리가 가능한 이유
3. 메시지 처리
- 메시지는 해당 토픽을 구독한 컨슈머에 의해 처리됨
- 이때, 메시지의 순서가 중요할 경우, 각 파티션 내에서 메시지의 순서 보장 가능
- 컨슈머는 메시지를 처리한 후, 오프셋을 커밋하여 다음에 읽어야 할 메시지 위치를 기록
- 자동 commit: poll() 호출 시, 자동으로 갱싱
- 수동 commit: 컨슈머 로직에서 직접 commit() 메서드를 호출
토픽 vs 파티션
토픽
토픽은 특정 유형의 메시지 스트림을 나타내는 논리적 이름이다. 예를 들어 주문 데이터 스트림의 경우 "orders"라는 토픽으로, 사용자 활동 로그는 "user_activity"라는 토픽으로 관리될 수 있다.
즉, 토픽은 단순히 메시지를 분류하는 이름, 즉 카테고리이다.
파티션
토픽 내에서 메시지는 여러 파티션에 나누어 저장된다. 각 파티션은 순서를 유지하며 독립적은 로그 파일로 관리된다.
각 파티션은 병렬 처리를 가능하게 하여 카프카의 확장성과 성능을 높이는 핵심 요소가 된다.

참고
https://aws.amazon.com/ko/what-is/apache-kafka/
https://medium.com/@jc3wrld999/kafka-broker-cluster-zookeeper-54c56d637b1
그리고... chat gpt
'DataEngineering' 카테고리의 다른 글
| [Apache Spark] 스트림 데이터 처리 (2) | 2024.08.04 |
|---|---|
| [Apache Airflow] Apache Airflow 기반의 데이터 파이프라인 CH2 정리 (0) | 2024.07.25 |
| [Apache Airflow] 도커로 환경 구축하기 (0) | 2024.07.24 |
| [Apache Airflow] Apache Airflow 기반의 데이터 파이프라인 CH1 정리 (2) | 2024.07.24 |
| [ELK 스택] ElasticSearch (0) | 2024.07.02 |



