[Apache Kafka] 실시간으로 사람 detect하고 집계 테이블 만들기
1. YOLO를 사용해서 실시간으로 사람 detect하기
시간별로 사람이 몇 명 있었는지 집계하는 테이블을 만들기 위해 먼저 YOLO를 사용한다.
(저는 YOLOv8을 사용하였습니다! )
https://github.com/ultralytics/ultralytics
GitHub - ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONNX > OpenVINO > CoreML > TFLite
NEW - YOLOv8 🚀 in PyTorch > ONNX > OpenVINO > CoreML > TFLite - ultralytics/ultralytics
github.com

이미 pre trained 모델이기 때문에 바로 사람이랑 휴대폰을 인식하는 걸 확인할 수 있다.
2. 카프카로 metaData 전송하기
모델이 이미 훈련되어 있으므로 다양한 객체를 인식할 수 있지만 우리가 궁금한 건 사람 객체이므로 cell phone이 아닌 사람이 인식된 시간과 바운딩 박스의 정보를(대충 좌표 정보라고 생각하고) 카프카에 전송해야 한다.
먼저 카프카 토픽 부터 먼저 생성한다.
1) 도커 카프카 컨테이너 안으로 들어간다
docker exec -it {카프카 컨테이너id} /bin/bash
2) --create옵션을 사용하여 people-metadata 토픽 생성하기
/opt/bitnami/kafka/bin/kafka-topics.sh --create --topic people-metadata --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1
3) 카프카 토픽 리스트 확인하기
/opt/bitnami/kafka/bin/kafka-topics.sh --list --bootstrap-server localhost:9092
잘 생성된 것을 확인할 수 있다!
4) 카프카 프로듀서를 통해 데이터 전송하기
#카프카 프로듀서 설정
producer = KafkaProducer(
bootstrap_servers=['localhost:9092'],
value_serializer= lambda v: json.dumps(v).encode('utf-8')
)
#데이터 전송 함수 정의
#def send_data(metaData):
producer.send('people-metadata', metaData)
producer.flush()
먼저 KafkaProducer() 를 사용해서 프로듀서 객체를 생성한다. 이때, bootstrap_servers 옵션을 사용하여 브로커 주소를 설정하고, vlaue_serializer를 사용하여 데이터를 직렬화한다.
send()함수를 사용하여 정의한 데이터를 전송한다.
#데이터 전송 코드(일부분)
for box, track_id, cls in zip(boxes, track_ids, clss):
x, y, w, h = box
now_time = datetime.today().strftime("%Y/%m/%d %H:%M:%S")
label = str(names[cls])
if label == 'person':
metaData= {
"id": track_id,
"timestamp": now_time,
"x": float(x - w),
"y": float(y - h),
}
send_data(metaData)
만약 인식된 객체의 label이 person이라면, id, timestamp, x좌표, y좌표로 metadata를 정의하고 앞에서 정의한 send_data()를 사용해서 데이터를 전송한다. (근데 카프카 이렇게 쓰는거 맞나..?)
/opt/bitnami/kafka/bin/kafka-console-consumer.sh --topic people-metadata --bootstrap-server localhost:9092 --from-beginning
메시지가 잘 전달 되었는지 확인해보았다.

3. 카프카 컨슈머에서 데이터 읽고 집계 테이블 생성 + 적재하기
카프카 컨슈머를 통해서 데이터를 읽고 집계 테이블을 만들어서 mongoDB에 적재할 수 있게 했다.
1) consumer 객체 생성
consumer = Consumer({
'bootstrap.servers': 'localhost:9092',
'group.id': 'mygroup',
'auto.offset.reset': 'earliest'
})
consumer.subscribe(['people-metadata'])
카프카 consumer 객체를 생성한다.
booststrap.servers: 브로커 주소를지정
group.id: 컨슈머 그룹 ID를 지정(컨슈머 그룹 ID를 설정하면 같은 그룹 내에 있는 컨슈머들이 메시지를 분산 처리할 수 있음!)
auto.offset.reset: 초기 오프셋을 설정, 컨슈머가 토픽을 처음 구독할 때 메시지를 어디서부터 읽을지 결정
subscribe()로 컨슈머가 구독한 토픽을 지정해준다.
2) 데이터 집계 및 mongdb에 적재
if timestamp:
utc_time = datetime.strptime(timestamp, '%Y/%m/%d %H:%M:%S')
hour = utc_time.strftime('%Y-%m-%d %H:00:00')
if hour not in aggregate_data:
aggregate_data[hour] = set()
aggregate_data[hour].add(id)
for hour, id in aggregate_data.items():
try:
collection.update_one(
{'hour': hour},
{'$set': {'count': len(id)}},
upsert=True
)
except Exception as e:
print(f"Error saving to MongoDB: {e}")
시간별로 집계 테이블을 만들었다.
hour을 딕셔너리의 key로 두어서 만약 딕셔너리에 hour가 없으면 새로운 set을 생성한 다음 해당 시간 대에 있는 사람의 if를 set()안에 추가했다.
그리고 hour와 count를 collection에 추가한다!
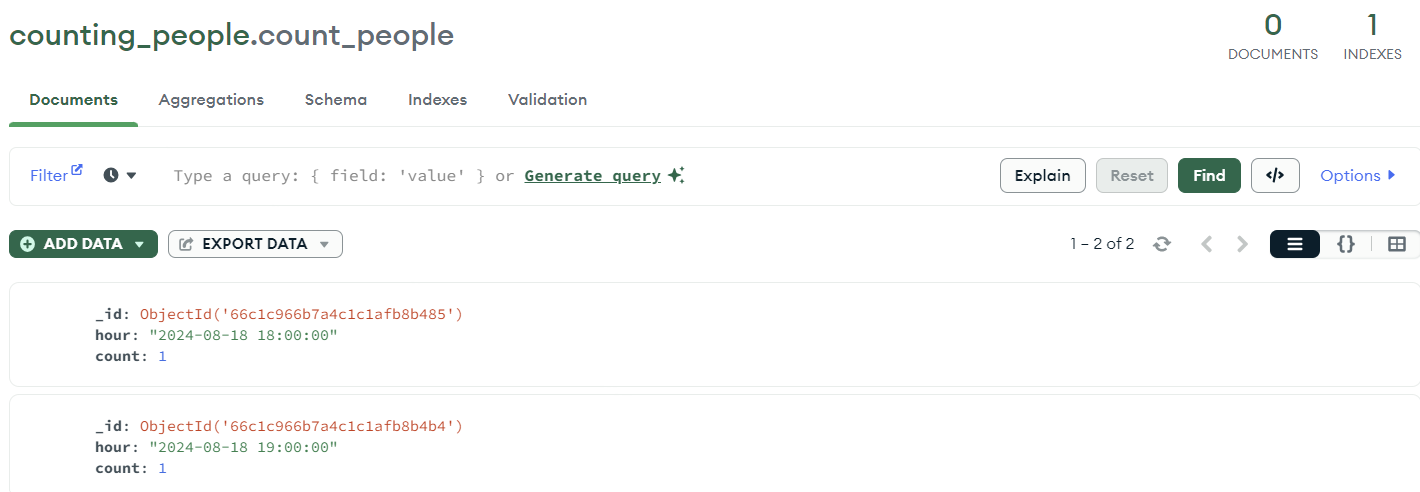
mongoDB에 데이터가 잘 추가 된 것을 확인할 수 있다
원래는 스파크랑 카프카 연동해서 집계 하고 싶었는데 실패해서 어쩌다보니 그냥 카프카 실습한 사람 됨..🧎
다음주에는 스파크랑 카프카 연동해서 집계 테이블 생성하기 성공해오겟습니다.
근데 진짜 이거...이렇게 하는게 맞나...? 하면서도 음...이게 맞나 이러고 있네
전체 코드 깃헙 주소
https://github.com/YEERRIn/Practice/tree/master/detect_and_count_people
Practice/detect_and_count_people at master · YEERRIn/Practice
Contribute to YEERRIn/Practice development by creating an account on GitHub.
github.com